
celina의 이것저것
주키퍼랑 카프카랑 하둡을 이용한 분산처리 본문
먼저 세개의 노드를 켜고 주키퍼를 켜서 상태를 확인해보면 leader와 follower들을 알 수 있다.
첫번째 두번째가 follower이고, 세번쨰가 leader이다.

그 다음 카프카를 이용할건데
[root@node1 config]# vi server.properties 여기서 설정을 파티션의 개수를 5개로 해준다
[root@node1 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
[root@node1 kafka]# jps
881 QuorumPeerMain
1393 Jps
1372 Kafka
카프카를 켜준다
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --topic test --create --replication-factor 3
Created topic test.카프카 토픽을 하나 생성하고
[root@node1 kafka]# bin/kafka-topics.sh --boop-server node1:9092 --topic test --describe상세조회를 해보면
Topic: test TopicId: jmEsHT58TfuatTgyfo4Efg PrtitionCount: 5 ReplicationFactor: 3 Configs:
Topic: test Partition: 0 Leader: 2 replicas: 2,0,1 Isr: 2,0,1
Topic: test Partition: 1 Leader: 1 replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 2 Leader: 0 replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 3 Leader: 2 replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 4 Leader: 1 replicas: 1,0,2 Isr: 1,0,2이렇게 뜬다
파티션을 5개로 했으니 5개가 뜨고, 현재 노드를 3개 쓰고 있어서 0,1,2가 뜬다
보면은 각 파티션마다 리더의 번호가 다르다.
- 복제본(Replicas): 파티션의 복사본으로, 데이터의 내구성과 고가용성을 보장
- ISR (In-Sync Replicas): 리더와 동기화된 상태로 데이터를 가진 복제본들의 집합
이제 여기서 노드2의 카프카를 종료하고 다시 보면

isr에서 1이 사라진걸 볼 수 있다 그리고 리더에서 1도 사라졌다
그 이유는 isr 은 동적으로 변화하는 리스트라서 서버2가 죽으니까 값이 바뀐걸 확인할 수 있는것이다
그리고 노드2를 다시 켜면

isr에서 1이 다시 생긴다 하지만 노드2가 한번 죽었었어서 리더에는 여전히 1이 존재하지 않는다
그리고 리더 재선출이라는게 있는데
[root@node1 bin]# kafka-leader-election.sh --boottrap-server node1:9092 --election-type preferred -all-topic-partitions
Successfully completed leader election (PREFERRED for partitions test-1, test-4이렇게 리더를 재선출한다.

다시 리더에 1이 생겼다!!!
[root@node1 kafka]# zkCli.sh -server node1:2181
Connecting to node1:2181여기로 들어가서
[zk: node1:2181(CONNECTED) 1] ls /
[admin, brokers, cluster, config, consumers, contoller, controller_epoch, feature, isr_change_notiication, latest_producer_id_block, log_dir_event_otification, zookeeper]
[zk: node1:2181(CONNECTED) 2] get /brokers
null
[zk: node1:2181(CONNECTED) 3] ls /brokers
[ids, seqid, topics]
[zk: node1:2181(CONNECTED) 5] ls /brokers/ids
[0, 1, 2]
// 노드2 끄고 이거 입력하면 1이 사라짐
[zk: node1:2181(CONNECTED) 6] ls /brokers/ids
[0, 2]
[zk: node1:2181(CONNECTED) 10] get /brokers/ids/0
{"features":{},"listener_security_protocol_map":{PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT:/node1:9092"],"jmx_port":-1,"port":9092,"host":"noe1","version":5,"timestamp":"1716433804963"}
[zk: node1:2181(CONNECTED) 11] get /controller
{"version":2,"brokerid":2,"timestamp":"171643379906","kraftControllerEpoch":-1}
[zk: node1:2181(CONNECTED) 12] get /controller_epch
1이런 명령어들을 입력하면 이제 뭐가 많이뜬다. 원래 주키퍼만 연결했을때는 별로 없었는데 카프카를 이용하니까 많이 생김
브로커의 아이디를 입력하면 아까 그 0,1,2도 볼 수 있다
******************************************************************************************************************************************
이제 하둡도 이용한다
싹다 끄고
/root/etc/hadoop/~~~~/hadoop으로 가서
[root@node1 hadoop]# vi core-site.xml
[root@node1 hadoop]# vi hdfs-site.xml
[root@node1 hadoop]# vi slaves
각각 파일을 수정해준다 이건 node1에서만 입력을한다
왜냐면
[root@node1 hadoop]# vi transfer.sh이렇게 실행파일을 하나 만들어서 scp?? 이걸로 node2,3에게 한꺼번에 보내면 되기 때문이다
[root@node1 hadoop]# chmod 777 transfer.sh이렇게 만들고 실행하면 된다
그리고 namenode초기화하고 start-dfs.sh를 node1에서만 해준다

그럼 node1은 네임노드, 나머지는 데이터노드가 된다!!!
[root@node1 hadoop]# hdfs dfs -mkdir /test폴더 하나 만들고
[root@node1 hadoop]# dd if=/dev/urandom of=dummy 024 count=150000
150000+0 records in
150000+0 records out
153600000 bytes (154 MB, 146 MiB) copied, 5.1069130.1 MB/s이렇게 대용량의 더미파일을 하나 만들 수 있다.
[root@node1 hadoop]# hdfs dfs -put dummy /test로컬에서 hdfs로 올려준다
node2에서 확인하면
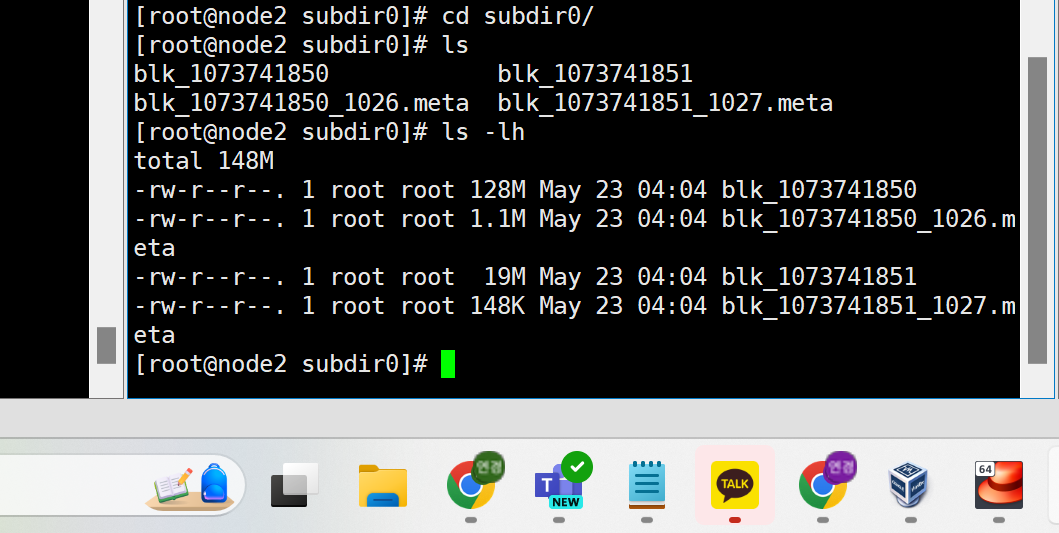
이렇게 뜬다

